
Rでファイルを読み込むときの文字化け対策【Statistics with “R”】
Rでデータ分析の課題をやったり、自分でデータをいじっているとよく直面する問題があります。
それが「文字化け」です。
今回は簡単に文字化けを回避するおまじないについて解説します。
データの読み込みでよく使われるのが read.csv 関数ですね。
read.csv(ファイル名)と入力することで、データを読み込むことができます。
番号,身長,体重
1,165,56
2,167,61
3,161,53
上のファイルをメモ帳に張り付けてdata.csvという名前で保存します。
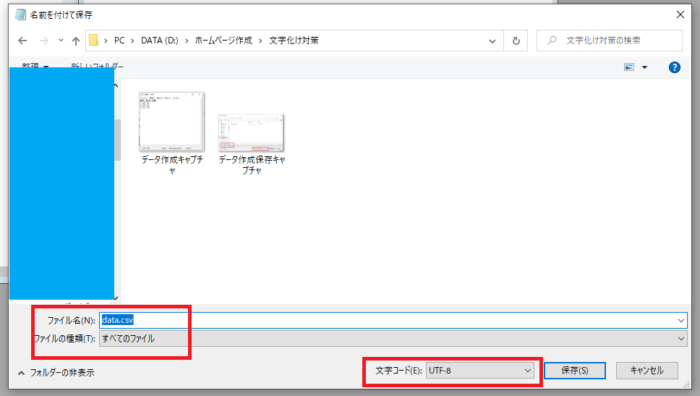
今回は文字コードをUTF-8にしました。
わざとRのエンコーディングをShift-JISとUTF-8に変更しながら同じ命令でデータを読んでみましょう。
options(encoding=”SJIS”)でR側のエンコーディングをShift-JISに変更しています。
setwd(“D:/ホームページ作成/文字化け対策”)はdata.csvを置いたフォルダですので適宜変更してください。
options(encoding="SJIS")
setwd("D:/ホームページ作成/文字化け対策")
read.csv("data.csv",header=T)
options(encoding="UTF8")
setwd("D:/ホームページ作成/文字化け対策")
read.csv("data.csv",header=T)
すると以下のような出力が得られます。
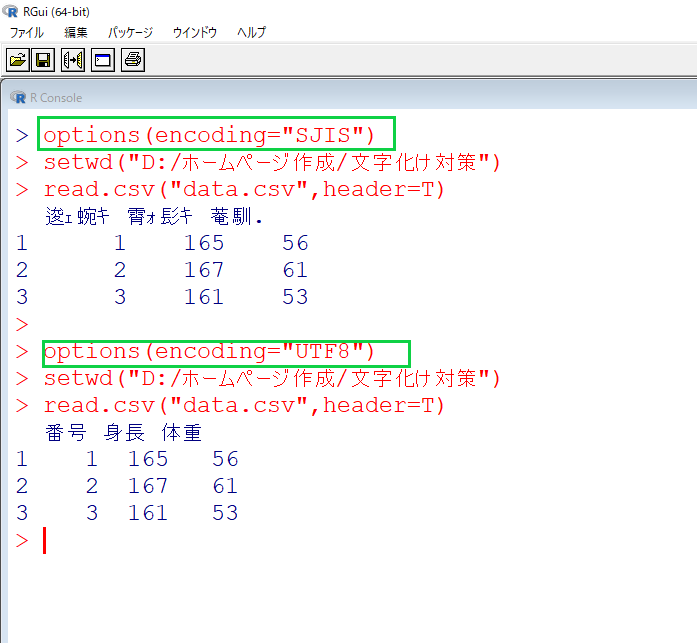
同じread.csv(“data.csv”,header=T)なのに、上側では文字化けが起きています。
しかしoptions(encoding=”UTF8″)のあとでは文字化けが起きていません。
これは、data.csvを保存するときに用いた「文字コード」とRの文字コードが一致していないために起きる現象です。
文字化けを回避するには、これらを一致させる必要があります。
しかし文字コードにはいろいろあり、調べるのが面倒かもしれません。
そんな時は以下のように書くと文字コードを調べられます。
install.packages("rvest")
library(rvest)
guess_encoding("data.csv")
実行結果は以下のようになりました。
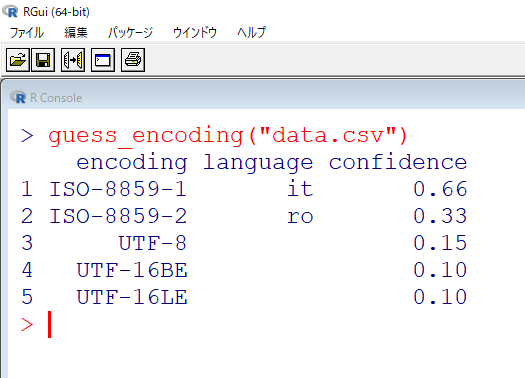
上から順番に可能性の高い文字コードが並んでいるので、試してみましょう。
Rのエンコードをguess_encodingが可能性が高いと言う順に変えて試してみます。
options(encoding=guess_encoding("data.csv")[[1]][1])
read.csv("data.csv",header=T)
options(encoding=guess_encoding("data.csv")[[1]][2])
read.csv("data.csv",header=T)
options(encoding=guess_encoding("data.csv")[[1]][3])
read.csv("data.csv",header=T)
options(encoding=guess_encoding("data.csv")[[1]][4])
read.csv("data.csv",header=T)
options(encoding=guess_encoding("data.csv")[[1]][5])
read.csv("data.csv",header=T)
その結果がこちらです。
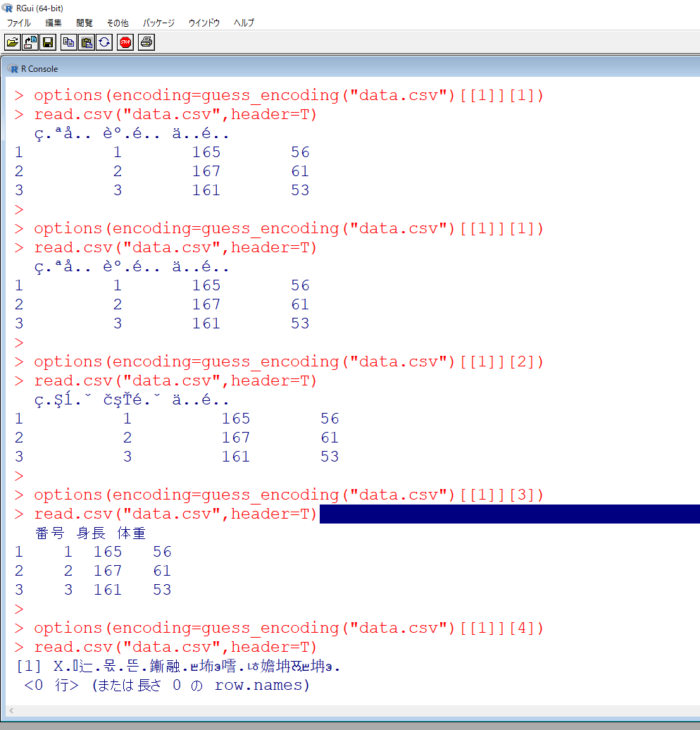
この結果、UTF-8が正しい文字コードだとわかります。
何故1番可能性が高い文字コードではなかったのでしょうか?
それは今回例に挙げたファイルdata.csvが小さかったからです。
ファイルが小さかったため、正しい文字コードを推測するための情報が不足し、予測に誤差が出たのです。
大きなデータを扱う場合には単に
library(rvest)
data <- data.frame(read.csv("data.csv",header=T,encoding=guess_encoding("data.csv")[[1]][1]))
と書くだけで、optionを変更する必要なく正しい文字コードでデータを読むことができます。
make.names(col.names, unique = TRUE) でエラー:
‘<94>ԍ<86>’ に不正なマルチバイト文字があります
のようなエラーメッセージが出た時も、
encoding=guess_encoding(“data.csv”)[[1]][1])
を用いることでデータを読み込むことができるようになります。
guess_encodingのかわりにhtml_encoding_guessを用いて
library(rvest)
data <- data.frame(read.csv("data.csv",header=T,encoding=html_encoding_guess("data.csv")[[1]][1]))
と書いてもうまくいきます。
